Generative AI has disrupted the art world and has transformed how we experience creativity, innovation, and aesthetics entirely. It compels artists to realign their approach to their craft, allowing them to create complex and dynamic artworks that would have been impossible to produce otherwise and opening up a new era of creative possibilities, where algorithms can create art that is both novel and aesthetically pleasing.
As generative AI continues to redefine the art world, more and more companies are leveraging this technology to create stunning and innovative works of art. In this blog, we will cover some you don’t want to miss. But first, let’s understand —
How Does AI Create Images From Scratch?

Image-generating AI tends to rely on what’s known as Generative Adversarial Networks (GANs) to do their bidding. GANs are a type of machine learning model that uses two neural networks to produce new, synthetic data. The first network creates new data based on random input. The second network, the discriminator, evaluates the data produced by the generator and decides whether it is realistic or not.
The first network’s goal is to create data that is indistinguishable from real data, while the discriminator’s goal is to identify fake data. These two networks are trained together, with the first and second networks continuously improving their ability to create realistic data and identify fake data, respectively.
The result is a powerful system capable of generating new, realistic data based on a set of learned patterns.
GANs are preferred because of their ability to learn complex, non-linear relationships between inputs and outputs, making them well-suited for generating rich and diverse data. GANs have been used to generate a wide variety of data, including images, music, and even 3D models. Creators also use them to replicate image composition and style, and super-resolution, where a low-resolution image is upscaled to a higher resolution.
Despite their many successes, GANs still face several challenges, including the risk of mode collapse, where the generator produces only a limited set of outputs and the difficulty of training the generator and discriminator in a balanced manner. GANs remain a powerful tool for generating new data with the potential to reform several industries, from art and design to medicine and robotics.
Check out these 7 tools that have disrupted the art and design world.
7 Image-Generating AI Tools You Need To Know About
1. Stable Diffusion
Stable Diffusion is a text-to-image model that enables you to generate fresh, unique, and interesting high-quality images without cutting holes in their pockets. It specializes in generating APIs — application programming interfaces — that companies and individuals can easily add to various applications.
Like any machine learning platform, the AI is ‘fed’ a training dataset. The software iteratively refines a set of initial samples to generate new ones using the training data. Hence, the model progressively refines its data through several diffusion steps to create realistic images.

One advantage of Stable Diffusion is that it can generate high-quality diverse samples, that is, it can create a wide range of realistic images or text that are not merely a reiteration of the existing data but an original art piece. It has been shown to perform well on a variety of benchmark datasets and is being actively researched. However, like many advanced machine learning techniques, Stable Diffusion is computationally intensive and requires significant resources to train and deploy.
2. DALL-E 2
DALL-E 2 is another advanced AI model developed by OpenAI that generates high-quality images from textual descriptions. It is the successor to the original DALL-E model, which gained widespread attention in early 2021 for its ability to generate a wide range of unique and creative images from textual prompts.
Like its predecessor, DALL-E 2 is based on a variant of the GPT architecture, a powerful deep learning model used for a variety of natural language processing tasks.

What’s new in DALL-E 2?
The new improved model incorporates new techniques such as dynamic routing and enhanced sparse attention to generate more complex and detailed novel images that have never been seen before.
Given a textual prompt such as “an armchair in the shape of an avocado,” DALL-E 2 can produce a high-quality image of exactly that. It can also generate images of animals, vehicles, landscapes, and other types of objects and scenes.
You can use it in a vast range of industries, including advertising, design, and entertainment. For example, one can have custom images for online ads or create concept art for movies and video games with a team of just one person.
3. Playground AI
Playground AI is a dynamic tool that generates images from scratch using a variety of advanced machine-learning techniques and textual descriptions. The user types the description of what they want or selects a predefined prompt from the Playground AI interface.
For example, they may input “a green apple on a table” or select a prompt like “generate a picture of a bird.” The textual input is encoded into a numerical format that can be processed by the AI model.
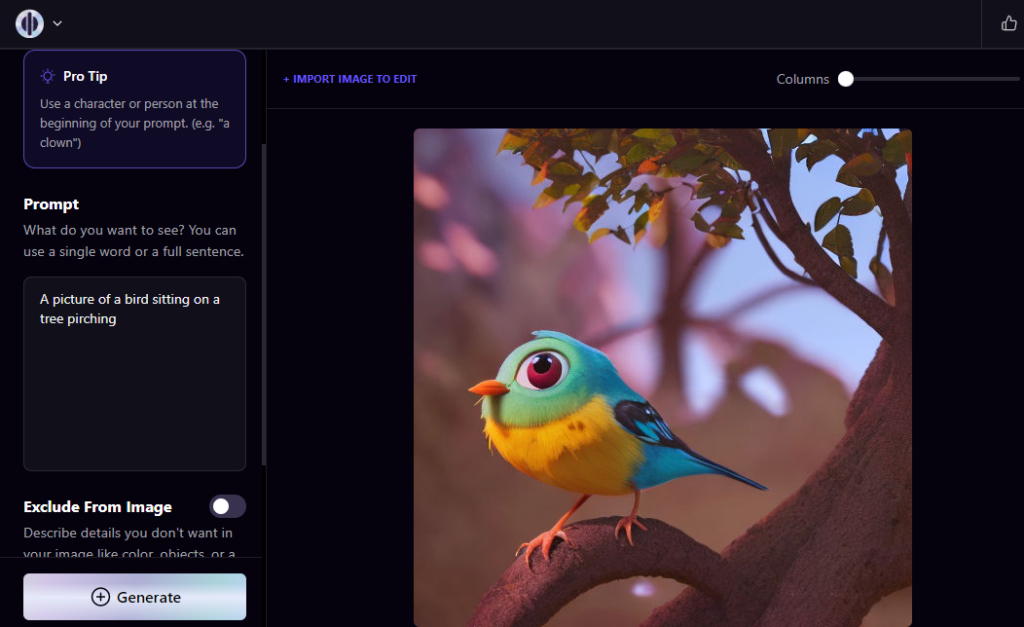
This is typically done using natural language processing techniques to extract the meaning and context of the input. The AI model generates an image based on the encoded input using advanced machine learning techniques, such as generative adversarial networks (GANs) or autoencoders. These models have been trained on large datasets of images to generate unique images that match the style and content of the input. The generated image may undergo additional processing to refine its quality and ensure it matches the input as closely as possible.
This may involve adjusting the colors, shapes, or other visual elements of the image. The final generated image is displayed to the user, who can then save it or continue to refine the input and generate additional images.
All in all, Playground AI makes it easy for anyone to create custom images without specialized skills or experience in graphic design. This can help level the playing field and enable more people to create high-quality visual content.
4. Midjourney
Midjourney is one of the most popular AI programs. Developed and hosted by an independent research lab in San Francisco, this model operates through a Discord bot on their official server. Users can generate images using the ‘/imagine’ command followed by their prompt.
The bot returns a set of four images that users can choose to upscale. Midjourney is also developing a web interface. Whenever you generate an image using Midjourney, it automatically gets publicly posted on the Discord server. While it reinforces the sense of building in the community, it also means your content is accessible to every other member and prone to get copied.

Midjourney provides excellent documentation that guides users through getting started and using its advanced features. These features include using different model versions, upscaling images, blending multiple images, and controlling various parameters. Once users understand these options, they can achieve genuinely impressive results.
Tools like Midjourney provide new opportunities for advertisers, such as creating custom ads, special effects, and more efficient e-commerce advertising. In June of 2022, the Economist used Midjourney to create the front cover for an issue.
5. NeuralStyler
NeuralStyler is an AI-powered video tool used for tasks like transferring the style of famous paintings onto photographs and generating unique and personalized videos.
The tool uses deep learning algorithms by first training a deep neural network on a large dataset of images, allowing it to learn the style of various images. Once trained, the software can be used to transfer the style of one set of images onto another, resulting in a new piece based on the content of the original and reference videos.

It operates by first breaking down the reference into its constituent styles elements, such as color, texture, and shapes. The quality of the reference video is significant as it can impact the output.
6. Archi-AI
Archi-AI is a cutting-edge generative AI software designed for architectural design and visualization. Its software aims to automate and simplify the process of architectural design by using deep learning algorithms to generate design proposals based on user input and constraints. Archi-AI operates by first learning from a large dataset of architectural designs and images to understand the structure and style of various building types.
The tool will use this information to generate design proposals based on user input and constraints, such as building type, location, and desired aesthetic style. One of the key advantages of Archi-AI is its ability to generate design proposals quickly and efficiently, allowing architects and designers to save time and focus on other aspects of the design process. It also has the potential to generate innovative and unique designs that might not have been possible using traditional design methods.
Archi-AI faces challenges such as the risk of generating low-quality or unrealistic designs, as well as the need for human oversight to ensure that the generated designs are safe and feasible. But overall, Archi-AI offers a new and innovative approach to architectural design and visualization with the potential to impact the real estate and construction industries.
7. Pikazo
Pikazo is a unique generative software that uses AI for creating art and designs from regular images. It is used for a slew of tasks, such as generating new designs and patterns and creating abstract images for backgrounds or wallpapers.
Pikazo uses deep learning algorithms to generate new images based on a user’s input image, enabling users to create unique and personalized art with ease. It operates per the parameters of DALL-E 2 and NeuralStyler— by first training a deep neural network on a large dataset of images to learn the styles and patterns of various art and designs. Once trained, it leverages the input image to design a fresh one.
Like NeuralStyler, the user can select a desired style and adjust various parameters to control the output image, resulting in an image that combines the content of the original image with the style of the selected style. One of the key advantages of Pikazo is its ability to generate unique artistic renditions and transfer this style onto, say, a photograph of your cat. Additionally, it has a simple user interface and requires no technical knowledge, making it accessible to a wide range of users.
The only limitation is the quality of the input image and the selected style. Sometimes, the resulting image may not reflect the intended style because the reference images are not optimal.
Overall, Pikazo is a highly innovative tool in the field of AI-powered art and design, offering a fresh approach to generating artsy and design-versions of pre-existing images.
What does the future hold?
The extensive use of AI to generate fresh and unique high-quality images poses a threat to arts and questions the need of learning the skill; it democratizes bringing your imagination to reality without acquiring the skills or the need to learn the craft. Anyone can create images and art given that they have enough context, reference images, and the ability to use the tool and write precise descriptions.
But it also means we can expect a powerful and enhanced visual experience. Creators, marketers, and businesses can leverage AI to generate stimulating and thought-provoking images without spending hours on Adobe or Affinity suites at a budget. You can create multiple high-quality iterations at a fraction of the time and cost. We’re excited to see how AI will shape how we think about and experience creative expression in the coming years.